Kafka_深入探秘者(8):kafka 高级应用
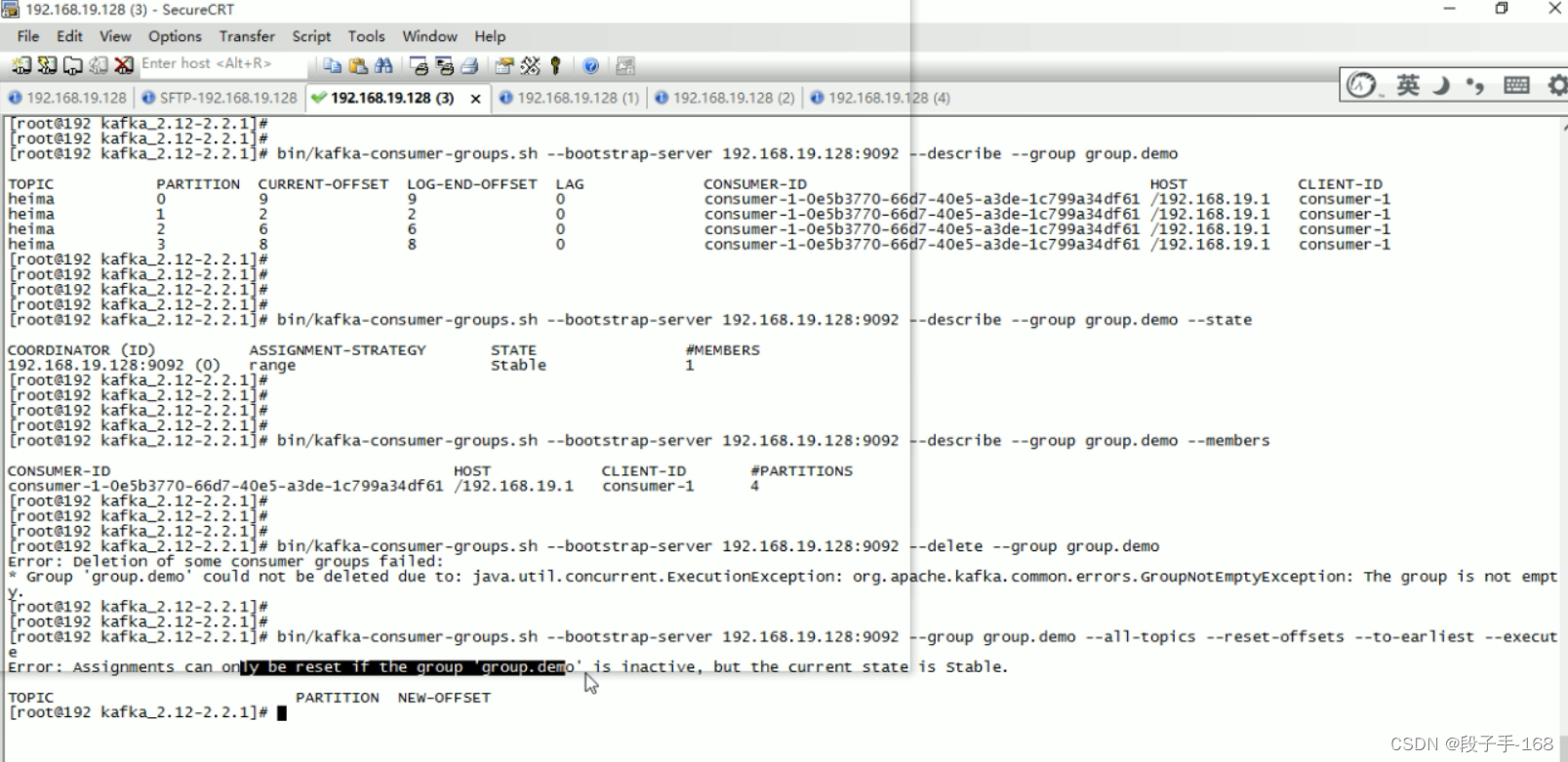
一、kafka 消费组管理
1、kafka 命令行工具
参考官网: http://kafka.apache.org/22/documentation.html
2、kafka 消费组管理:查看消费组
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110:9092 --list
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --list
# 查看消费组命令
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
3、kafka 消费组管理:查看消费组详情
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110:9092 --describe --group group.demo
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --describe --group group.demo
# 查看消费组详情命令(group.demo 是你自己创建的需要查看的组名)
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group.demo
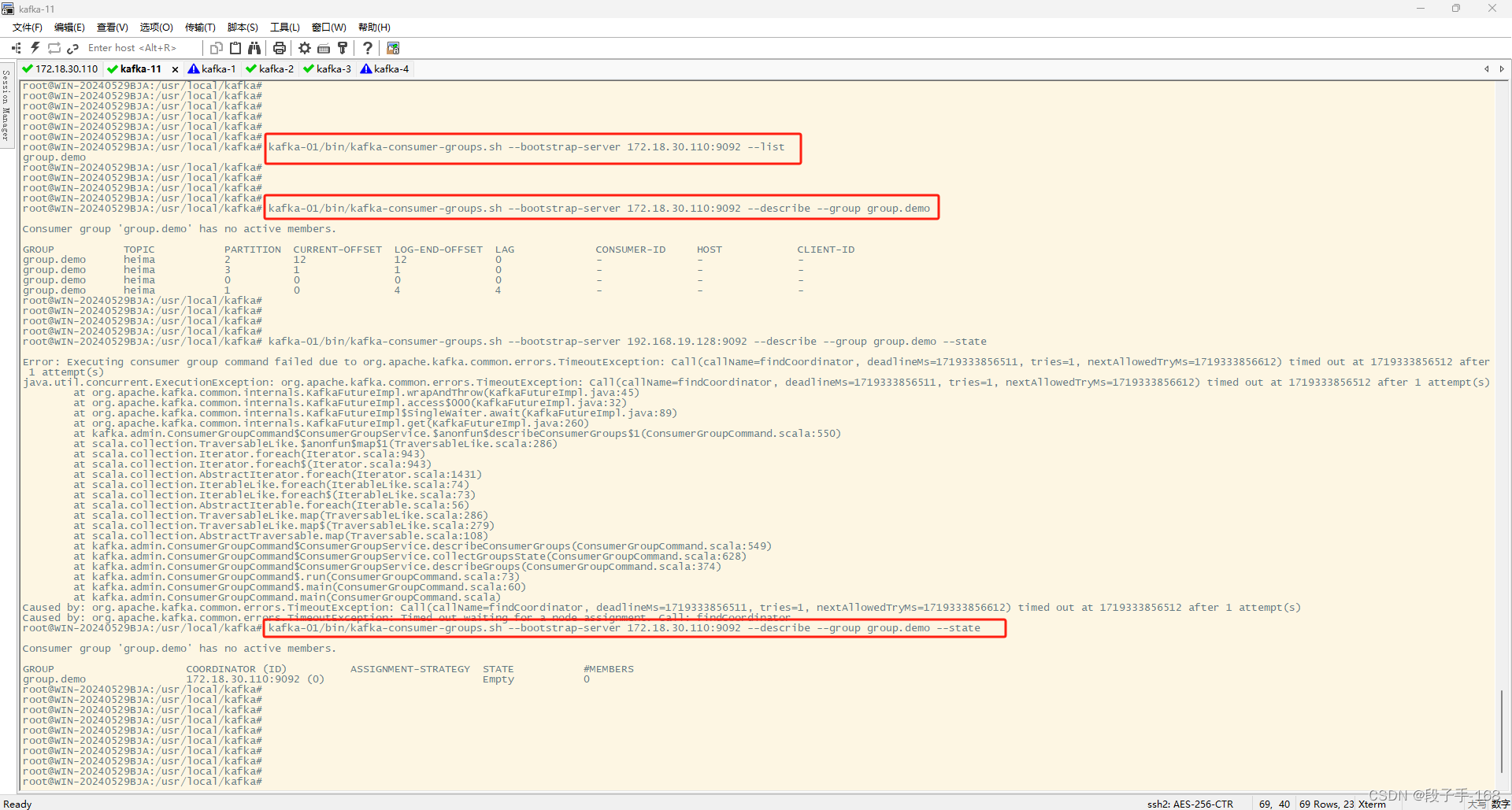
4、kafka 消费组管理:查看消费组当前状态
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110:9092 --describe --group group.demo --state
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --describe --group group.demo --state
# 查看消费组当前状态
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group.demo --state
5、kafka 消费组管理:查看消费组内成员信息
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110:9092 --describe --group group.demo --members
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --describe --group group.demo --members
# 查看消费组内成员信息
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group.demo --members
6、kafka 消费组管理:删除消费组,如果有消费者在使用,则会删除失败。
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110 --delete --group group.demo
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --delete --group group.demo
# 删除消费组,如果有消费者在使用,则会删除失败
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group group.demo
7、kafka 消费位移管理:重置消费位移,如果有消费者在使用,则会重置失败。
1)kafka 重置消费位移命令:
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group group.demo --all-topics --reset-offsets --to-earliest --execute
2)命令参数说明:
–all-topics :指定了所有主题。
–reset-offsets :重置消费。
–to-earliest :移到最后
–execute :开始执行命令
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 或者
cd /usr/local/kafka/kafka_2.12-2.2.1/
# 重置消费位移,如果有消费者在使用,则会重置失败
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group group.demo --all-topics --reset-offsets --to-earliest --execute
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128):
bin/kafka-consumer-groups.sh --bootstrap-server 172.18.30.110:9092 --group group.demo --all-topics --reset-offsets --to-earliest --execute
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.19.128:9092 --group group.demo --all-topics --reset-offsets --to-earliest --execute
二、kafka 数据管道 Connect 文件系统
1、kafka 数据管道 Connect 文件系统 概述
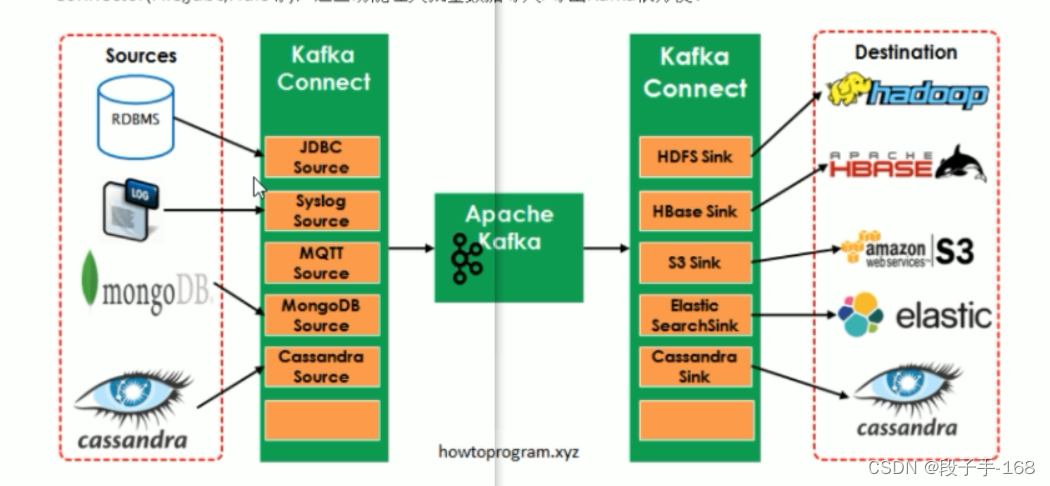
1)Kafka 是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析)。为何集成其他系统和解耦应用,经常使用 Producer 来发送消息到 Broker,并使用 Consumer 来消费 Broker 中的消息。Kafka Connect 是到 0.9 版本才提供的并极大的简化了其他系统与 Kafka 的集成。
2)Kafka Connect 运用用户快速定义并实现各种 Connector(File,dbc,Hdfs等),这些功能让大批量数据导入/导出 Kafka 很方便。
3)在 Kafka Connect 中还有两个重要的概念: Task 和 Worker。
4)Connect 中一些概念:
-
连接器: 实现了 ConnectAPI,决定需要运行多少个任务,按照任务来进行数据复制,从 work 进程获取任务配置并将其传递下去。
-
任务: 负责将数据移入或移出 Kafka。
-
work 进程: 相当与 connector 和任务的容器,用于负责管理连接器的配置、启动连接器和连接器任务,提供 RESTAPI。
-
转换器: kafka connect 和其他存储系统直接发送或者接受数据之间转换数据。
2、kafka 独立模式-文件系统
场景
以下示例使用到了两个 Connector,将文件 source.txt 中的内容通过 Source 连接器写入 Kafka 主题中,然后将内容写入 srouce.sink.txt 中。
- FileStreamSource: 从 source.txt 中读取并发布到 Broker 中。
- FileStreamSink: 从 Broker 中读取数据并写入到 source.sink.txt 文件中。
3、步骤详情
3.1、首先我们来看下 Worker 进程用到的配置文件
${(KAFKA_HOME}/config/connect-standalone.properties
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
// Kafka 集群连接的地址(把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110 或:192.168.19.128))
# bootstrap.servers=localhost:9092
bootstrap.servers=172.18.30.110:9092
# 打开并编辑 config/connect-standalone.properties 文件
vim config/connect-standalone.properties
# 修改以下几项:
# 启动端口,注意不能冲突
rest.port=8084
// 格式转化类
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
// json消息中是否包含schema
key.converter.schemas.enable=true
value.converter.schemas.enable.true
// 保存偏移量的文件路径
offset.storage.file.filename=/tmp/connect.offsets
// 设定提交偏移量的频率
offset.flush.interval.ms=10808
3.2 其中的 Source 使用到的配置文件是 $KAFKA_HOME}/config/connect-file-source.properties
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 打开并编辑 config/connect-file-source.properties 文件
vim config/connect-file-source.properties
# 修改以下几项:
//配置连接器的名称
name.local-file-source
//连接器的全限定名称,设置类名称也是可以的
connector.class=FileStreamSource
// task数量
tasks .max=1
//数据源的文件路径(修改为你自己创建source.txt文件实际路径)
file=/tmp/source.txt
// 主题名称(修改为你自己创建的主题,如:heima)
# topic=topic0703
topic=heima
3.3 其中的 Sink 使用到的配置文件是 $KAFKA_HOME}/config/connect-file-sink.properties
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
# 打开并编辑 config/connect-file-sink.properties 文件
vim config/connect-file-sink.properties
# 修改以下几项:
name=local-file-sink
connectér.class=FileStreamsink
tasks.max=1
# 修改为你自己创建sink.txt文件实际路径
#file=/tmp/source.sink.txt
file=/tmp/sink.txt
# 修改为你自己创建的主题,如:heima
#topics=topice703
topics=heima
3.4 启动 source 连接器
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties
3.5 启动 slink 连接器
# 切换到 kafka 安装目录
cd /usr/local/kafka/kafka_2.12-2.8.0/
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink.properties
3.6 source 写入文本信息
# 写入消息到 source.txt
echo "hello kafka,coming">> /tmp/source.txt
# 查询是否写入成功
less /tmp/source.txt
# 同时查询sink.txt 是否有内容传输过来
cat /tmp/sink.txt
三、kafka springboot+kafka 001
1、打开 idea 创建 artifactId 名为 kafka_spring_learn 的 maven 工程。
--> idea --> File
--> New --> Project
--> Maven
Project SDK: ( 1.8(java version "1.8.0_131" )
--> Next
--> Groupld : ( djh.it )
Artifactld : ( kafka_spring_learn )
Version : 1.0-SNAPSHOT
--> Name: ( kafka_spring_learn )
Location: ( ...\kafka_spring_learn\ )
--> Finish
2、在 kafka_spring_learn 工程的 pom.xml 文件中导入依赖坐标。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>djh.it</groupId>
<artifactId>kafka_spring_learn</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<!-- <relativePath></relativePath>-->
</parent>
<properties>
<java.version>8</java.version>
<!-- <scala.version>2.11</scala.version>-->
<scala.version>2.12</scala.version>
<slf4j.version>1.7.21</slf4j.version>
<!-- <kafka.version>2.0.0</kafka.version>-->
<kafka.version>2.8.0</kafka.version>
<lombok.version>1.18.8</lombok.version>
<junit.version>4.11</junit.version>
<gson.version>2.2.4</gson.version>
<protobuff.version>1.5.4</protobuff.version>
<!-- <spark.version>2.3.1</spark.version>-->
<spark.version>2.4.8</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.version}</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>${gson.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>${protobuff.version}</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>${protobuff.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_2.11</artifactId>
<version>2.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3、在 kafka_spring_learn 工程,创建 application.properties 配置文件。
# kafka_spring_learn\src\main\resources\application.properties
logging.level.root=INFO
# spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
# IP 地址换成你自己的虚拟机 IP 地址
#spring.kafka.producer.bootstrap-servers=192.168.19.128:9092
#spring.kafka.consumer.bootstrap-servers=192.168.19.128:9092
spring.kafka.producer.bootstrap-servers=172.18.30.110:9092
spring.kafka.consumer.bootstrap-servers=172.18.30.110:9092
4、在 kafka_spring_learn 工程,创建 KafkaLearnApplication.java 启动类文件。
/**
* kafka_spring_learn\src\main\java\djh\it\kafkalearn\KafkaLearnApplication.java
*
* 2024-6-24 创建 KafkaLearnApplication.java 启动类文件
*/
package djh.it.kafkalearn;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@RequestMapping
//避免Gson版本冲突快捷配置
@EnableAutoConfiguration(exclude = {org.springframework.boot.autoconfigure.gson.GsonAutoConfiguration.class})
public class KafkaLearnApplication {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaLearnApplication.class);
public static void main(String[] args) {
SpringApplication.run(KafkaLearnApplication.class, args);
}
@RequestMapping("/index")
public String index(){
return "hello,kafka spring comming";
}
@Autowired
private KafkaTemplate template;
private static final String topic = "heima";
// 消息生产者
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input){
this.template.send(topic, input);
return "Send success! " + input;
}
//消息的接收
@KafkaListener(id ="", topics = topic, groupId = "group.demo")
public void listener(String input){
LOGGER.info("message input value:{}", input);
}
}
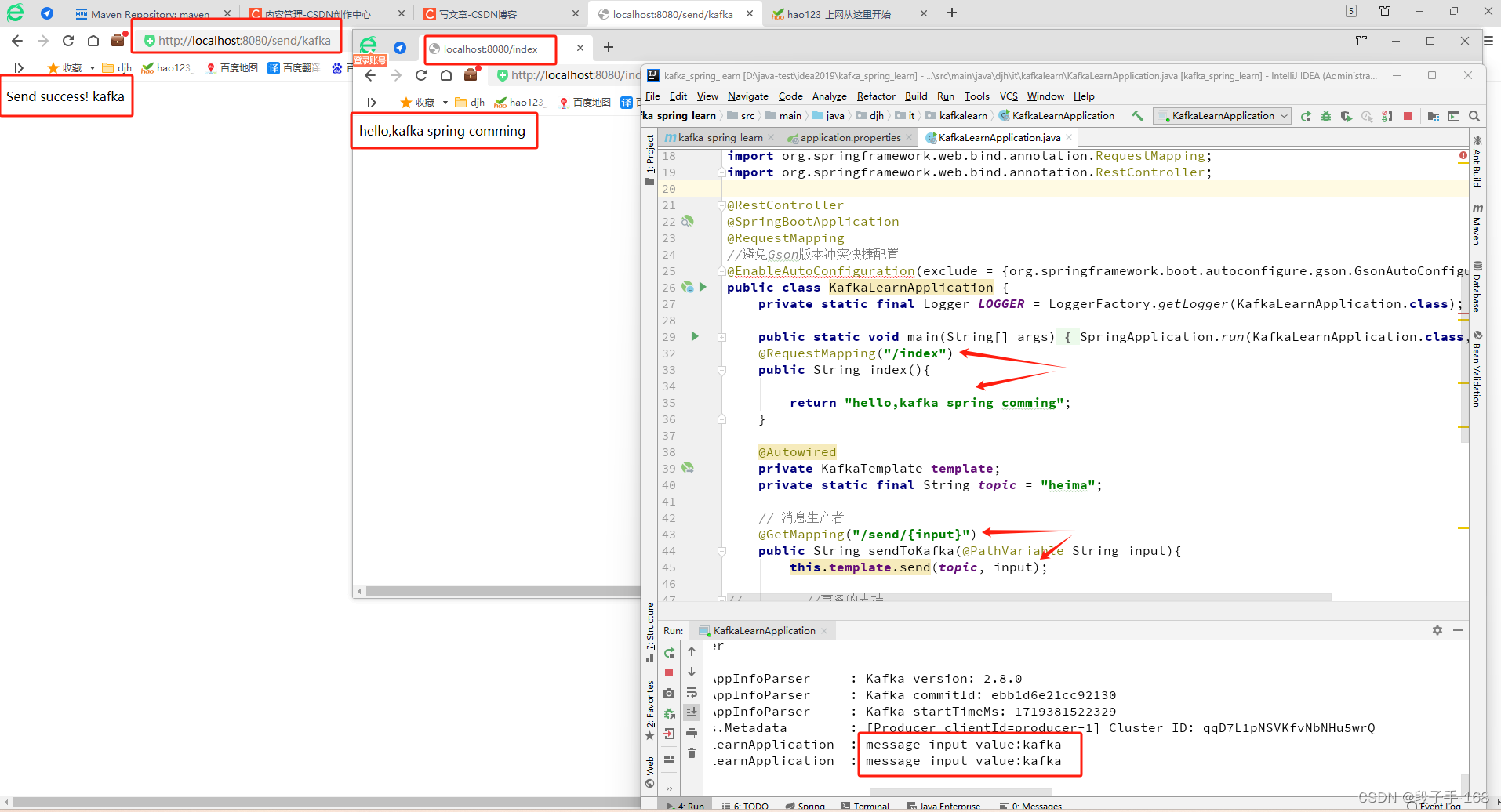
5、启动 KafkaLearnApplication.java 启动类,进行测试。
1)浏览器地址栏输入: localhost:8080/index
输出: hello,kafka spring comming
2)浏览器地址栏输入: localhost:8080/send/kafka
输出: Send success! kafka
四、kafka springboot+kafka 事务 001
1、在 kafka_spring_learn 工程中,修改 application.properties 配置文件,添加事务。
# kafka_spring_learn\src\main\resources\application.properties
logging.level.root=INFO
# spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
# IP 地址换成你自己的虚拟机 IP 地址
#spring.kafka.producer.bootstrap-servers=192.168.19.128:9092
#spring.kafka.consumer.bootstrap-servers=192.168.19.128:9092
spring.kafka.producer.bootstrap-servers=172.18.30.110:9092
spring.kafka.consumer.bootstrap-servers=172.18.30.110:9092
# 事务的支持
spring.kafka.producer.transaction-id-prefix=kafka_tx.
2、在 kafka_spring_learn 工程中,修改 KafkaLearnApplication.java 启动类,添加事务。
/**
* kafka_spring_learn\src\main\java\djh\it\kafkalearn\KafkaLearnApplication.java
*
* 2024-6-24 创建 KafkaLearnApplication.java 启动类文件
*/
package djh.it.kafkalearn;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@RequestMapping
//避免Gson版本冲突快捷配置
@EnableAutoConfiguration(exclude = {org.springframework.boot.autoconfigure.gson.GsonAutoConfiguration.class})
@Transactional
public class KafkaLearnApplication {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaLearnApplication.class);
public static void main(String[] args) {
SpringApplication.run(KafkaLearnApplication.class, args);
}
@RequestMapping("/index")
public String index(){
return "hello,kafka spring comming";
}
@Autowired
private KafkaTemplate template;
private static final String topic = "heima";
// 消息生产者
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input){
this.template.send(topic, input);
//事务的支持
template.executeInTransaction(t ->{
t.send(topic, input);
if("error".equals(input)){
throw new RuntimeException("input is error");
}
t.send(topic, input+" anthor");
return true;
});
return "Send success! " + input;
}
//消息的接收
@KafkaListener(id ="", topics = topic, groupId = "group.demo")
public void listener(String input){
LOGGER.info("message input value:{}", input);
}
}
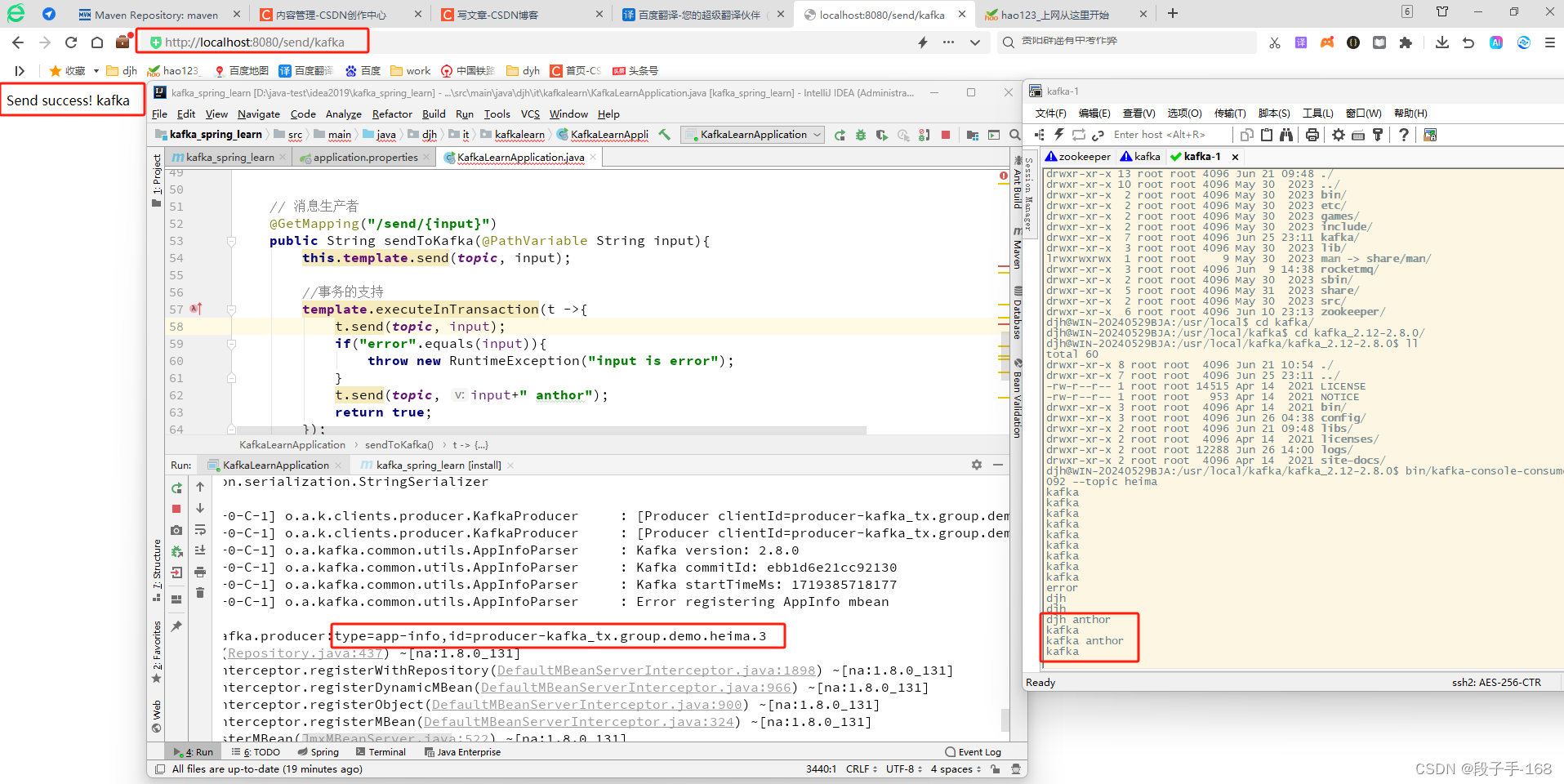
3、启动 KafkaLearnApplication.java 启动类,进行测试。
1)浏览器地址栏输入: localhost:8080/send/kafka
输出: Send success! kafka
2)浏览器地址栏输入: localhost:8080/send/error
会抛出异常。
五、kafka springboot+kafka 事务 002
1、在 kafka_spring_learn 工程中,修改 application.properties 配置文件,添加事务。
# kafka_spring_learn\src\main\resources\application.properties
logging.level.root=INFO
# spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
# IP 地址换成你自己的虚拟机 IP 地址
#spring.kafka.producer.bootstrap-servers=192.168.19.128:9092
#spring.kafka.consumer.bootstrap-servers=192.168.19.128:9092
spring.kafka.producer.bootstrap-servers=172.18.30.110:9092
spring.kafka.consumer.bootstrap-servers=172.18.30.110:9092
# 事务的支持
spring.kafka.producer.transaction-id-prefix=kafka_tx.
2、在 kafka_spring_learn 工程中,修改 KafkaLearnApplication.java 启动类,添加事务。
/**
* kafka_spring_learn\src\main\java\djh\it\kafkalearn\KafkaLearnApplication.java
*
* 2024-6-24 创建 KafkaLearnApplication.java 启动类文件
*/
package djh.it.kafkalearn;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@RequestMapping
//避免Gson版本冲突快捷配置
@EnableAutoConfiguration(exclude = {org.springframework.boot.autoconfigure.gson.GsonAutoConfiguration.class})
@Transactional
public class KafkaLearnApplication {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaLearnApplication.class);
public static void main(String[] args) {
SpringApplication.run(KafkaLearnApplication.class, args);
}
@RequestMapping("/index")
public String index(){
return "hello,kafka spring comming";
}
@Autowired
private KafkaTemplate template;
private static final String topic = "heima";
// 消息生产者
@GetMapping("/send/{input}")
public String sendToKafka(@PathVariable String input){
this.template.send(topic, input);
//事务的支持
template.executeInTransaction(t ->{
t.send(topic, input);
if("error".equals(input)){
throw new RuntimeException("input is error");
}
t.send(topic, input+" anthor");
return true;
});
return "Send success! " + input;
}
// 消息生产者2: 演示事务
@GetMapping("/send2/{input}")
@Transactional(rollbackFor = RuntimeException.class)
public String sendToKafkaTransaction(@PathVariable String input){
//事务的支持
template.send(topic, input);
if("error".equals(input)){
throw new RuntimeException("input is error2!");
}
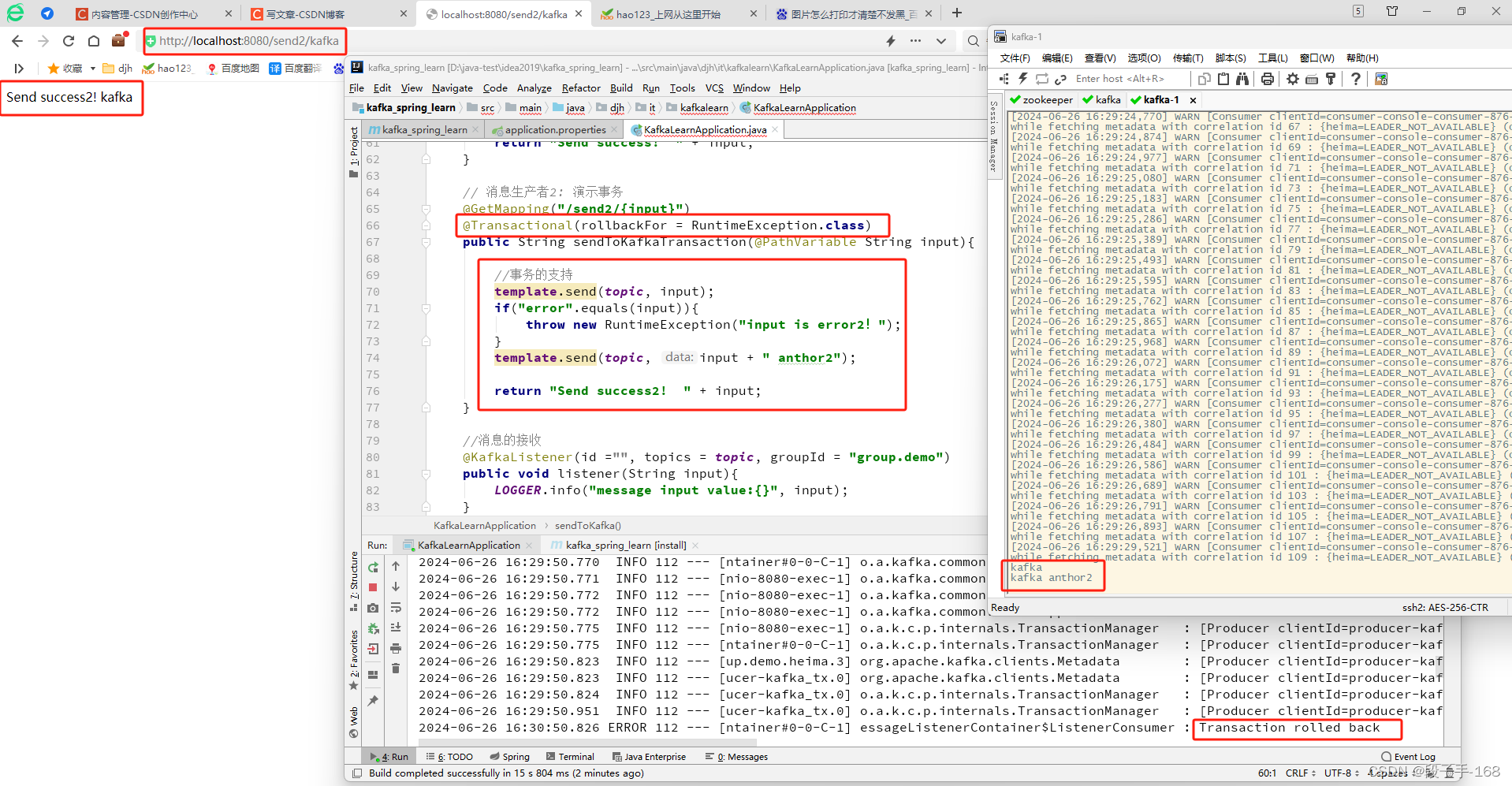
template.send(topic, input + " anthor2");
return "Send success2! " + input;
}
//消息的接收
@KafkaListener(id ="", topics = topic, groupId = "group.demo")
public void listener(String input){
LOGGER.info("message input value:{}", input);
}
}
3、启动 KafkaLearnApplication.java 启动类,进行测试。
1)浏览器地址栏输入: localhost:8080/send2/kafka
输出: Send success2! kafka
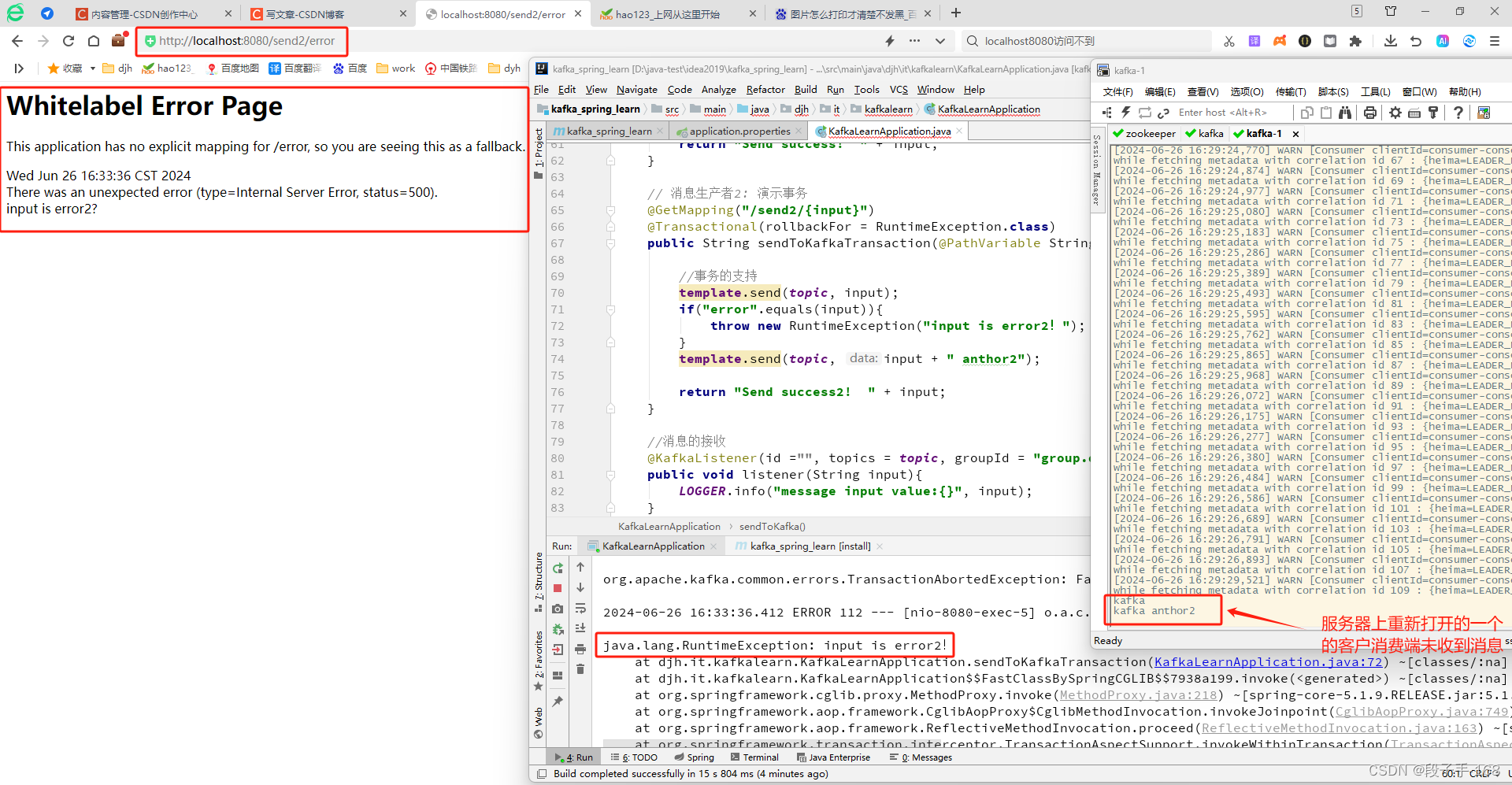
2)浏览器地址栏输入: localhost:8080/send2/error
会抛出异常。服务器上重新打开一个客户消费,也收不到消息。
4、消息中间件选型对比:
4.1 资料文档
Kafka: 中。有 kafka 作者自己写的书,网上资料也有一些,
rabbitmq: 多。有一些不错的书,网上资料多。
zeromq: 少。没有专门写 zeromg 的书,网上的资料多是一些代码的实现和简单介绍。
rocketmq: 少。没有专门写rocketmq的书,网上的资料良莠不齐,官方文档很简洁,但是对技术细节没有过多的描述。
activemq: 多。没有专门写activemq的书,网上资料多
4.2 开发语言
Kafka: Scala
rabbitmg: Erlang
zeromg:c
rocketmg: java
activemg: java
4.3 支持的协议
Kafka: 自己定义的一套.【基于TCP)
rabbitmg: AMQPI
zeromq: TCP、UDP
rocketmq: 自己定义的一套.
activemq: OpenWire、STOMP、REST、XMPP、AMQP
4.4 消息存储
Kafka: 内存、磁盘、数据库。支持大量堆积。
rocketmq: 磁盘。支持大量堆积。
rabbitmq: 内存、磁盘、支持少量规程。
activemq: 内存、磁盘、数据库。支持少量堆积。
zeromq: 消息发送端的内存或者磁盘中。不支持持久化。
4.5 消息事务
Kafka: 支持
rabbitmq: 支持。客户端将信道设置为事务模式只有当消息被 rabbitMq 接收,事务才能提交成功,否则在捕获异常后进行回滚。使用事务会使得性能有所下降
zeromq: 不支持
rocketmq: 支持
activemq: 支持。
4.6 负载均衡
Kafka: 支持负载均衡。
rabbitmq: 对负载均衡支持不好。
zeromq: 去中心化,不支持负载均衡。本身只是一个多线程网络库。
rocketmq: 支持负载均衡。
activemq: 支持负载均衡。可以基于 zookeeper 实现负载均衡。
4.7 集群方式:
Kafka: 天然的 Leader-Slave 无状态集群。
rabbitmq: 支持简单集群,复制模式,对高级集群模式支持不好。
zeromq: 去中心化,不支持集群。
rocketmq: 常用,多对 Master-Slave 模式。开源版本需手动切换 Slave 模式变成 Master 模式。
activemq: 。支持简单集群模式,比如 主-备,对高级集群模式支持不好。
4.8 管理界面
Kafka: 一般
rabbitmq: 好
zeromq: 无
rocketmq: 无
activemq: 一般
4.9 可用性
Kafka: 非常高(分布式)
rabbitmg: 高(主从)。
zeromg: 高。
rocketmq: 非常高(分布式)
activemq: 高(主从)
4.10 消息重复
Kafka:支持at least once、at most once
rabbitmg:支持at least once、at most once
zeromq:只有重传机制,但是没有持久化,消息丢了重传也没有用。既不是atleastonce、也不是at most
once、更不是exactly only once
rocketmq:支持atleast once
activemq:支持atleast once
4.11 吞吐量 TPS
Kafka: 极大
Kafka 按批次发送消,息和消费消,息。发送端将多个小消,息合并,批量发向 Broker,消费端每次取出一个批次的消,息批量外理。
六、kafka spark+kafka
1、流式处理 Spark
-
Spark 最初诞生于美国加州大学伯克利分校(UCBerkeley)的AMP实验室,是一个可应用于大规模数据处理的快速、通用引擎。
-
2013年,Spark 加入 Apache 孵化器项目后,开始获得迅猛的发展,如今已成为 Apache 软件基金会最重要的三大分布式计算系统开源项目之一(即 Hadoop、Spark、Storm)。
-
Spark 最初的设计目标是使数据分析更快–不仅运行速度快,也要能快速、容易地编写程序。
-
为了使程序运行更快,Spark 提供了内存计算,减少了迭代计算时的I0开销;
-
而为了使编写程序更为容易,Spark 使用简练、优雅的 Scala 语言编写,基于 Scala 提供了交互式的编程体验。
-
虽然,Hadoop 已成为大数据的事实标准,但其 MapReduce 分布式计算模型仍存在诸多缺陷,
-
而 Spark 不仅具备 Hadoop MapReduce 所具有的优点,且解决了 Hadoop MapReduce 的缺陷。
-
Spark 正以其结构一体化、功能多元化的优势逐渐成为当今大数据领域最热门的大数据计算平台。
2、Spark 安装与应用
Spark 官网下载:
http://spark.apache.org/downloads.html
https://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/
3、下载完成安装包,解压即安装
# 创建目录并切换目录:
mkdir /usr/local/spark/
cd /usr/local/spark/
# 上传安装包到服务器
sftp> put
# 解压即安装
tar -zxvf apark-2.4.4-bin-hadoop2.7
# 配置 JDK
vim sbin/spark-config.sh
# 你的 jdk 安装路径(java 默认安装路径:/usr/lib/jvm/java-8-openjdk-amd64/ )
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 切换到 spark 的安装目录
cd /usr/local/spark/apark-2.4.4-bin-hadoop2.7/
# 启动 spark
sbin/start-all.sh starting
# 验证
jps -l2819 kafka.Kafka
4、浏览器地址栏输入: http://localhost:8080
http://127.0.0.1:8080
http://172.18.30.110:8080
5、Spark 和 Kafka 整合:
5.1 在 kafka_spring_learn 工程中,创建 Spark 和 Kafka 整合 类 SparkStreamingFromKafka.java
/**
* kafka_spring_learn\src\main\java\djh\it\kafkalearn\spark\SparkStreamingFromKafka.java
*
* 2024-6-26 创建 Spark 和 Kafka 整合 类 SparkStreamingFromKafka.java
*/
package djh.it.kafkalearn.spark;
import lombok.SneakyThrows;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
public class SparkStreamingFromKafka {
@SneakyThrows
public static void main( String[] args ) {
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName(("SparkStreamingFromKafka"));
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "172.18.30.110:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "sparkStreaming");
Collection<String> topics = Arrays.asList("heima");
JavaInputDStream<ConsumerRecord<String, String>> javaInputDStream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
JavaPairDStream<String, String> javaPairDStream = javaInputDStream.mapToPair(new PairFunction<ConsumerRecord<String, String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call( ConsumerRecord<String, String> consumerRecord ) throws Exception {
return new Tuple2<>(consumerRecord.key(), consumerRecord.value());
}
});
javaPairDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, String>>() {
@Override
public void call( JavaPairRDD<String, String> javaPairRDD ) throws Exception {
javaPairRDD.foreach(new VoidFunction<Tuple2<String, String>>() {
@Override
public void call( Tuple2<String, String> tuple2 ) throws Exception {
System.out.println(tuple2._2);
}
});
}
});
streamingContext.start();
streamingContext.awaitTermination();
}
}
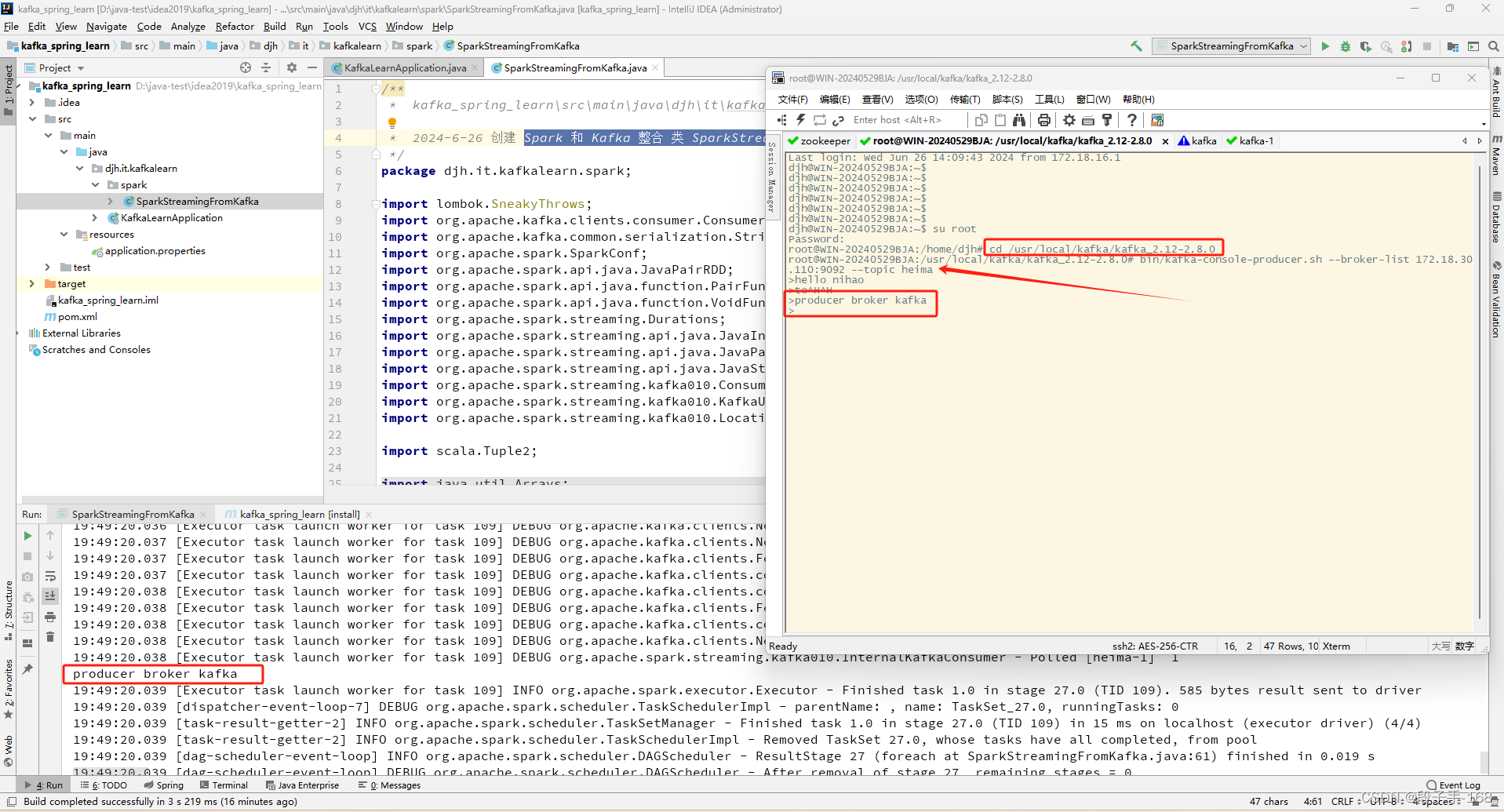
5.2、在服务器端打开一个生产消息发送服务,进行消息发送测试。
# 切换到 kafka 安装目录下:
cd /usr/local/kafka/kafka_2.12-2.8.0
# 打开生产消息服务:
bin/kafka-console-producer.sh --broker-list 172.18.30.110:9092 --topic heima
# 开始发送消息:
>hello nihao
>to^H^H
>producer broker kafka
>
# 在 idea 启动类控制台这边就会收到 消息,这就是 Spark 流式处理。
上一节关联链接请点击
# Kafka_深入探秘者(7):kafka 稳定性